Reminisce 
rand()
- Remember supercomputers? galaxy evolution
- The central Kafka joke... is that our endless and impossible journey toward our home... is our home.
-- as related by David Foster Wallace
- We fill pre-existing forms
and when we fill them
we change them
and are changed.
- It's excellence, not happiness, that we admire most.
- Where there's muck, there's brass
- Having somebody believe in you can make or break a human being.
- We must acknowledge that nobody is ever fully knowable -- maybe especially not those closest to us.
What animates and motivates others is very often a stew of secrets they will take to their graves.
-- from a review of "Just Lately Started Buying Wings: Missives From the Other Side of Silence"
- At twenty-nine [and again at thirty-nine] one exchanges a great vague possibility for a small hard reality
- Worship your body and beauty and sexual allure and you will always feel ugly.
Worship power, you will end up feeling weak and afraid, and you will need ever more power over others to numb you to your own fear.
Worship your intellect, being seen as smart, you will end up feeling stupid, a fraud, always on the verge of being found out.
....
[This] is unconsciousness, the default setting, the rat race, the constant gnawing sense of having had, and lost,
some infinite thing. -- David Foster Wallace
- "Fine, fine. Fine. Just completely fine. No problem at all. Happy to be here. Feeling better. Sleeping better. Love the chow. In a word, couldn't be finer. The grinding? The tooth-grinding? A tic. A jaw-strengthener. Expression of all-around fineness. Likewise the thing with the eyelid." -- Infinite Jest
- "In short, 99% of the head's thinking activity consists of trying to scare the everliving shit out of itself." -- Infinite Jest
- And it's this knowingness, a knowingness not based in or on knowledge or experience but simply in the recognition of the artifice at hand, that has arguably numbed us to ourselves, to each other, to love, to freedom, to activism and agitation and protest, to the very act of creating something unironic or nonmeta. ... Few of us, though, realistically, truly "know" the conventions that are forever being spoofed in the culture just about everywhere we turn. No matter. Thinking we know is good enough. Or so we thought.
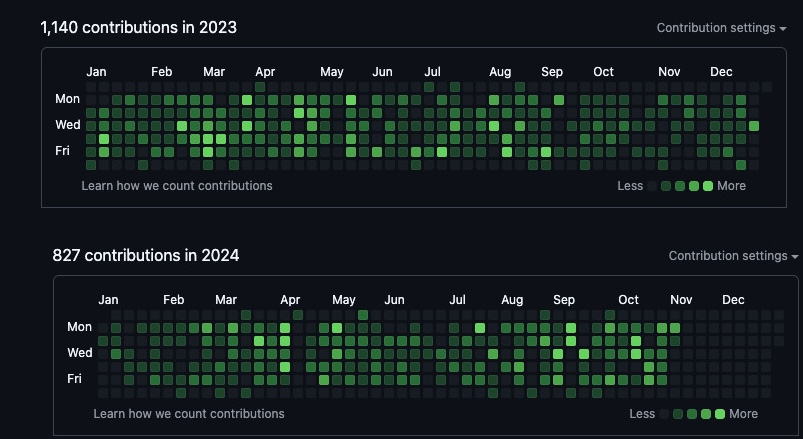
 icons next to the changes, plus then have matching
"Construction Ahead" road signs? Remember the need for line-eater
food preceeding Usenet posts? How about those ubiquitous final
.signature lines that defeated the theoretical NSA automated content snooping that
is actually in full-on use today, and thus would get you arrested?
icons next to the changes, plus then have matching
"Construction Ahead" road signs? Remember the need for line-eater
food preceeding Usenet posts? How about those ubiquitous final
.signature lines that defeated the theoretical NSA automated content snooping that
is actually in full-on use today, and thus would get you arrested?{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}